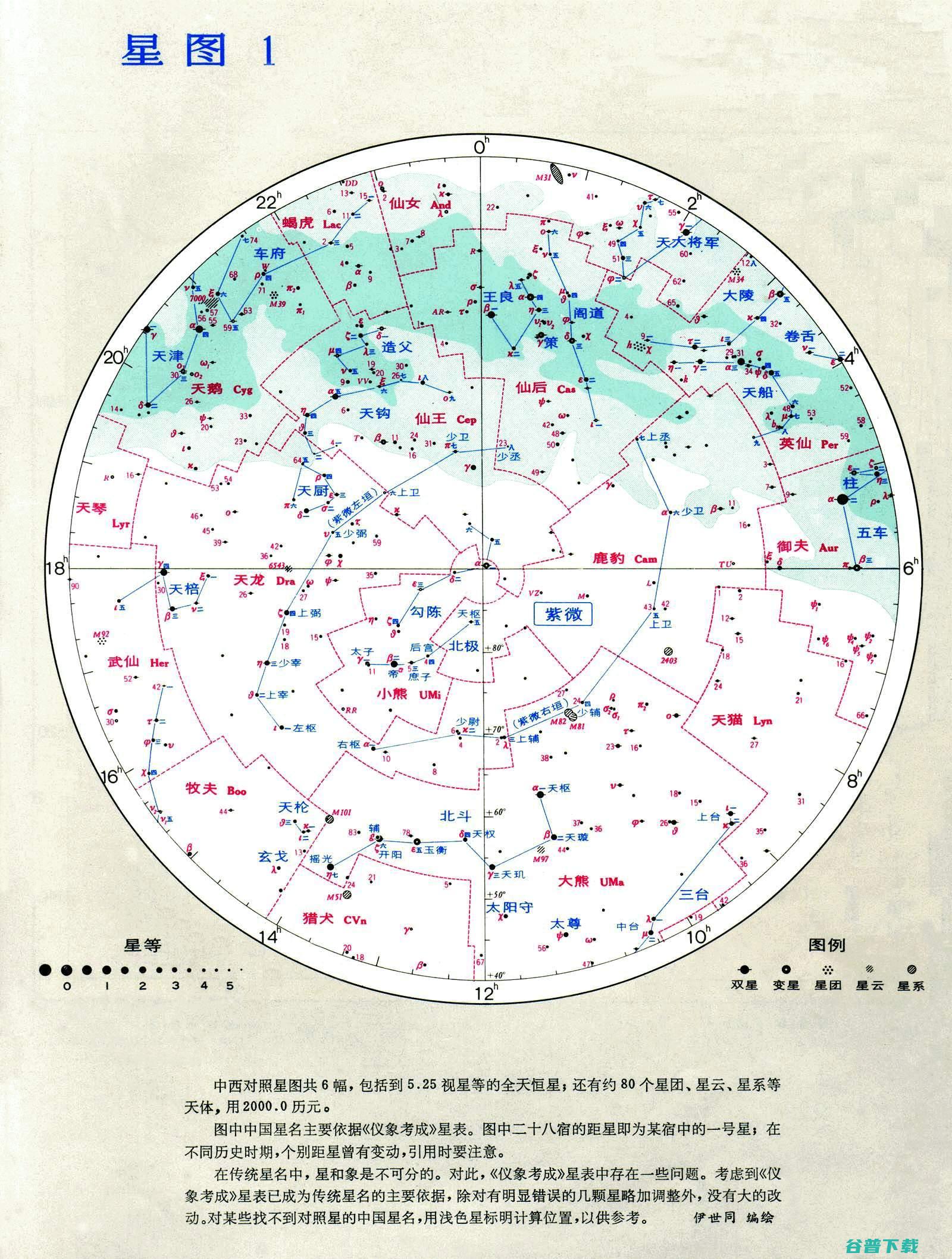
最新 少于两层的transformer GPT 且只有注意力块 (两层以上含两层不得设置防盗窗)
只有一层或两层、且只有注意力块的transformer,在性能上有望达到96层、兼具注意力块与MLP块的GPT,3的效果吗,在过去的两年里,基于Transformer架构开发的大规模语言模型在性能,如语言流畅度,上达到了令人叹为观止的效果,但是,Transformer对单词的处理方法是什么,学术界仍未有确定的答案,普遍的理解是,tra...。

只有一层或两层、且只有注意力块的transformer,在性能上有望达到96层、兼具注意力块与MLP块的GPT,3的效果吗,在过去的两年里,基于Transformer架构开发的大规模语言模型在性能,如语言流畅度,上达到了令人叹为观止的效果,但是,Transformer对单词的处理方法是什么,学术界仍未有确定的答案,普遍的理解是,tra...。

5月初,Meta发布了一个可以执行多个不同任务的大型语言模型,OpenpretrainingTransformer,OPT,175B,在过去几年里,大型语言模型,largelanguagemodel,LLM,已经成为人工智能研究的热点之一,在OpenAI发布包含1750亿参数的深度神经网络GPT,3之后,就引发了一场LLM的,军备竞...。

GoogleBrain的机器人团队,RoboticsatGoogle,最近发布了一篇文章,介绍了他们如何将大规模语言模型的,说,的能力和机器人,行,的能力结合在一起,从而赋予机器人更适用于物理世界的推理能力,physically,grounded,动机面对对方,我不小心洒了我的饮料,你可以帮我一下吗,的问题的时候,你会怎么反应,你...。